我做了一個埃及象形文字聖書體的輸入法,字符基於 Unicode 編碼。輸入法編碼有幾部分,每個基本符号都有一個 Gardiner code 的輸入方法,A-Z 爲大分類,每一個符号再接以數字,如 A、B、C、D 各代表男人、女人、人格化的神、人體部分。比如 𓀀 是 A1,𓏠 是 Y5 等等。
然後從1980年代起有一個埃及學家制訂的用 ASCII 碼轉寫聖書體的規則,稱作 Manuel de Codage ,簡稱 MdC 。在以上的分類形碼以外,還有音碼,每個音素用一個大寫或小寫字母表示。對於已知發音的符号(可以理解爲偏旁,包括意符、形旁和聲旁)也可以用音來表示。比如 𓏠 (Y5) 的發音是 mn 。和漢字一樣,聖書體的同音字和多音字都很多,但 MdC 爲了便於記憶及避免歧義,指定了一組單音素、二音素、多音素的基本符号,比如 i 就是 𓇋 ,而不會輸入同音的 𓀀 等字符。
因爲聖書體並非單一的從左到右線性書寫,MdC 還有組合規則,比如 ‘-’ 爲左右排列, ‘:’ 爲上下排列, ‘*’ 爲下一級的左右排列,即結合順序是先 * ,再 : ,再 - 。比如 Amenhotep 的名字如圖
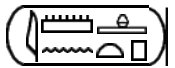
,在王名框(用 ‘< >’ 表示)內的符号從左向右、從上到下的符号讀音分別是 𓇋 i、𓏠 mn、𓈖 n、𓊵 Htp、𓏏 t、𓊪 p,則其 MdC 轉寫爲
1 | <-i-mn:n-Htp:t*p-> |
,Unicode 輸出爲 𓍹𓇋𓏠𓈖𓊵𓏏𓊪𓍺 。
當然了,因爲 rime 系輸入法有選字的功能,我們不必拘泥於嚴格的 MdC 規則而要求無歧義,而可以加入更多的編碼。一次輸入也可以輸入一個“字”甚至多個“字”,而不必一次只輸出一個偏旁/獨體字。
我這裏定的規則爲:輸入 MdC 的音碼,若以 ‘;’ 結尾則爲 MdC 標準所無的單個符号,而以 ‘~’ 結尾則輸出一個組合字。
例如 ‘mniw’ 輸出標準的 MdC 字符 𓀦 (A33),而 ‘mniw;’ 輸出同音的字符 𓀸 (A47),而 ‘mniw~’ 輸出同音的組合字 𓀰𓅱𓀀 (A42-w-A1)。如有更多的同音字也都在接 ‘;’ 或 ‘~’ 的碼裏面選,而不耽誤 MdC 的盲打。當然現在詞表還只是一個示意,非常不全,待以後慢慢補充了。
下載和安裝說明
rime聖書體下載: https://github.com/biopolyhedron/rime-hieroglyph-mdc
安裝好 小狼毫/trime/prime/中州韻/鼠鬚管 等輸入法後,將兩個 .yaml 文件複製入 rime 系輸入法的“用戶文件夾”後,“重新部署”即可運行。若未能自動加入本輸入法,可能需要在 default.custom.yaml 文件中的 patch/schema_list: 下加入一行
1 | - {schema: hieroglyph_mdc} |
再部署。
聖書體普通字符(U+13000 ~ U+1342F)若未能自動支持,可在 Win10 中査找 ‘Segoe UI Historic’ 字體( ‘seguihis.ttf’ 文件),或下載 ‘Noto Sans Egyptian Hieroglyphs’ 字體。而目前尚無能夠正確顯示聖書體字符組合(需要正確解釋控制符 U+13430 ~ U+1343F )的字體,不過在可以先加上控制符輸入着,假裝能夠看見正常的顯示,等待能夠正確顯示的字體出現。
其餘說明都在 hieroglyph_mdc.schema.yaml 的文件頭裏面,及自己看 hieroglyph_mdc.dict.yaml 就好了。
另外有能用 MdC 轉寫法正確顯示聖書體的 Java 小程序,叫 JSesh,在這裏下載: https://jsesh.qenherkhopeshef.org/
在我的 github https://github.com/biopolyhedron 裏面還有中古全拼和中古三拼,西夏文四角輸入法,及各種基於拉丁轉寫及 QWERTY 鍵盤的輸入方案(比如藏文、維吾爾文、蒙古文、滿文、緬文、朝鮮文、梵文天城體、拉丁字母(含各種附加符号,可輸入國際音標)、阿拉伯字母(含各種附加符号)、基利爾字母(可輸入俄文和新蒙文)等等,其中有部分是和其他朋友合作的。
假如您覺得我的輸入法特有用,下面有“打賞”按鈕,隨便給點兒就行。

