主要發現:《五體清文鑑》裏的察合臺文二十八宿的順序對錯了
我最近在錄入《五體清文鑑》的一些部分(整體太長了,只算我感興趣的地方),錄到二十八宿這裏。先是看滿語的二十八宿:
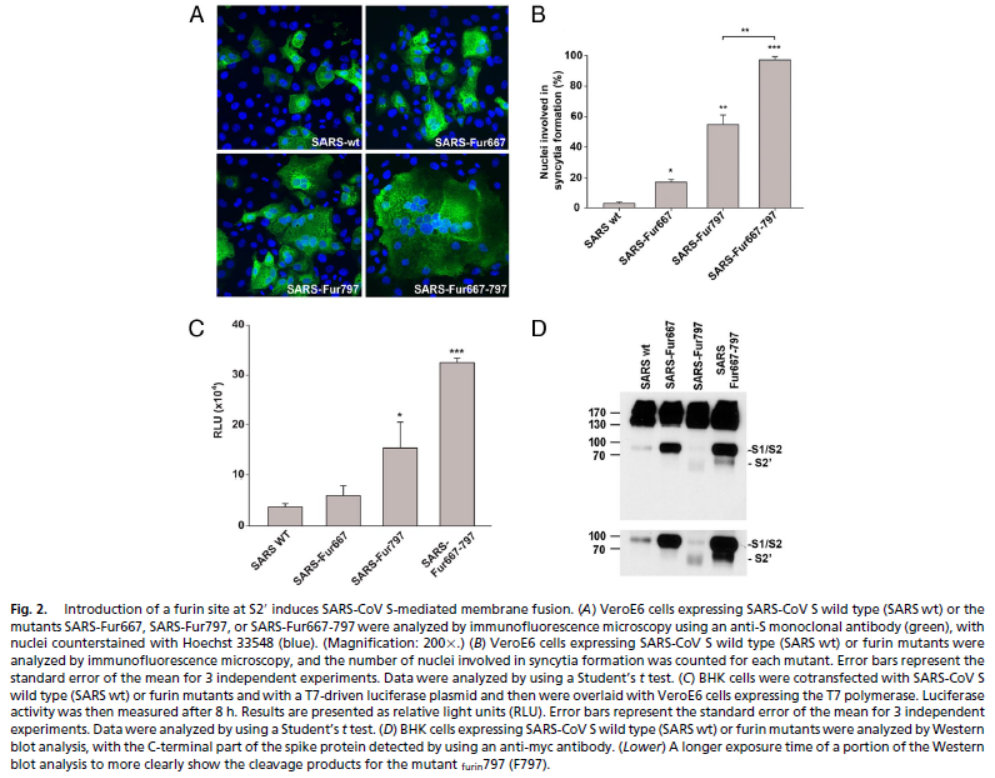
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|
| 角 gimda | 亢 k’amduri | 氐 dilbihe | 房 falmahvn | 心 sindubi | 尾 weisha | 箕 girha |
| 斗 demtu | 牛 niohan | 女 nirehe | 虚 hinggeri | 危 weibin | 室 xilgiyan | 壁 bikita |
| 奎 kuinihe | 婁 ludahvn | 胃 welh’vme | 昴 moko | 畢 bingha | 觜 semnio | 參 xebnio |
| 井 jingsitun | 鬼 guini | 柳 lirha | 星 simori | 張 jabhv | 翼 imhe | 軫 jeten |
挺顯然,每個詞的頭一個音節都是根據近代漢語音譯來的,但也難爲加這些不同的詞尾了。
我原是想通過《五體清文鑑》學察合臺文。看察合臺文得先會滿文(好在滿文拼寫容易)。察合臺文的Nastaliq小字眞是毀眼睛,筆畫特徵太不明顯了。


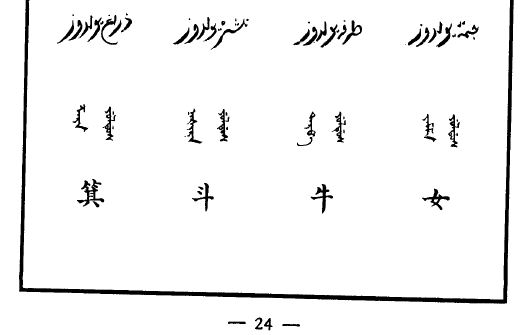
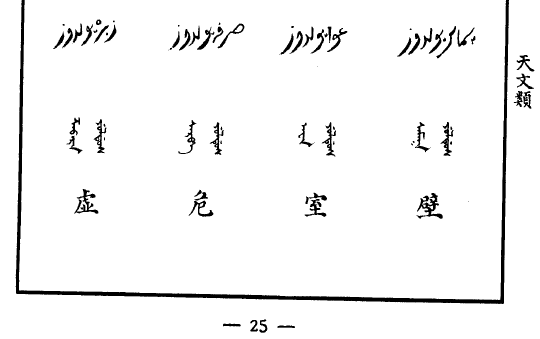


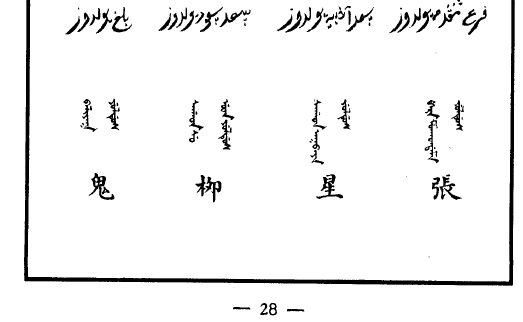

關鍵是想要校對,但讀出來的波斯/阿拉伯星象學或命理學信息在互聯网上很難搜到。不過總算找到一個网䈎( https://al-jazirah.com/2020/20201019/wo1.htm )明顯相關,但其拼寫和上面的還是明顯有區別,尤其是房宿對不上。但我終於把阿拉伯文的二十八宿按順序扒出來了。再然後,我發現《五體清文鑑》的氐宿 الثريا 自動翻譯出來居然是“昴宿”。然後還發現有兩個和心臟相關的詞, البطين (心室)和 القلب (心臟)。然後發現把阿拉伯的星座往後挪13位,所有的星座就都對上了!
看來是編《五體清文鑑》的人看中國和阿拉伯都有二十八宿,就強行從第一位對上了。結果沒注意各自的首位定的不一樣,中文以角宿起始,而阿拉伯以 الشرطان (婁宿)起始,察合臺跟從阿拉伯(但名稱略有區別),《五體清文鑑》就未加分辨直接配對ㄦ了。話說二十八宿名稱中文和阿拉伯文意義相關的不多,也就是心和尾對得比較準。
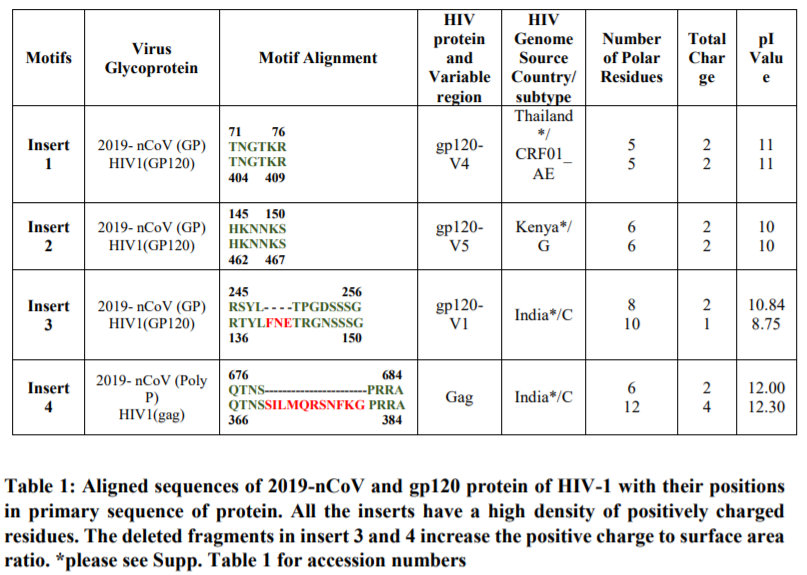
以下是二十八宿的察合臺文名攷證(顯示,尤其是滿文及滿文阿禮嘎禮有不正確的,請用“蒙满联合文鉴体”來正確顯示):
| 中文 | 察合臺文 | 滿文發音 | 擬轉寫 | 阿拉伯文 | 眞實對應(阿拉伯語義) |
|---|---|---|---|---|---|
| 角 | شراط يولدوز | ᡧᠠᡵᠠᡨ ᠶᡠᠯᡩᡠᠰ | šarāṭ | الشرطان | 婁(癌症) |
| 亢 | بطن يولدوز | ᠪᠠᡨᡝᠨ ᠶᡠᠯᡩᡠᠰ | baṭin | البطين | 胃(心室) |
| 氐 | شريّا يولدوز | ᡧᡳᡵᠠᡳᠶᠠ ᠶᡠᠯᡩᡠᠰ | širayyā | الثريا | 昴(昴) |
| 房 | عَينِ ٱلثوْرِڛْ يولدوز | ᠠᠶᡝᠨᡳᠯ ᠰᠠᠣᡵᡳᠰ ᠶᡠᠯᡩᡠᠰ | ˤayni-l þawris | الدبران | 畢 |
| 心 | هقعە يولدوز | ᡥᡡᡴ᠍ ᡠ ᠶᡠᠯᡩᡠᠰ | huqˤaʰ | الهقعة | 觜 |
| 尾 | هنعە يولدوز | ᡥᠠᠨ ᠠ ᠶᡠᠯᡩᡠᠰ | hanˤaʰ | الهنعة | 參 |
| 箕 | ذراغ يولدوز | ᡯᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | ðarāğ | الذراع | 井(肘) |
| 斗 | نشرە يولدوز | ᠨᠠᡧᡳᡵᠠ ᠶᡠᠯᡩᡠᠰ | našra | النثرة | 鬼(人中) |
| 牛 | طرفە يولدوز | ᡨᠠᡵᡦᠠ ᠶᡠᠯᡩᡠᠰ | ṭarfaʰ | الطرف | 柳 |
| 女 | جمّە يولدوز | ᠵᠠᠮᠮᠠ ᠶᡠᠯᡩᡠᠰ | jammaʰ | الجبهة | 星 |
| 虚 | زبرە يولدوز | ᡯᠠᠪᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | zabraʰ | الزبرة | 張 |
| 危 | صرفە يولدوز | ᠰᠠᡵᡦᠠ ᠶᡠᠯᡩᡠᠰ | ṣarfaʰ | الصرفة | 翼 |
| 室 | عوا يولدوز | ᠠᠸᠠ ᠶᡠᠯᡩᡠᠰ | ˤawā | العوا | 軫 |
| 壁 | ڛماک يولدوز | ᠰᠠᠮᠠᡴ ᠶᡠᠯᡩᡠᠰ | samāk | السماك | 角 |
| 奎 | عفرا يولدوز | ᠠᡦᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | ˤafrā | الغفر | 亢 |
| 婁 | زبانا يولدوز | ᡯᠠᠪᠠᠨᠠ ᠶᡠᠯᡩᡠᠰ | zabānā | الزبانا | 氐(蟹爪) |
| 胃 | اكليل يولدوز | ᠠᡴᠯᡳᠯ ᠶᡠᠯᡩᡠᠰ | akliyl | الإكليل | 房(花環) |
| 昴 | قلب يولدوز | ᡴᠠᠯᠪᡠ ᠶᡠᠯᡩᡠᠰ | qalbu | القلب | 心(心臟) |
| 畢 | شولە يولدوز | ᡧᡠᠯᠠ ᠶᡠᠯᡩᡠᠰ | ŝuwlaʰ | الشولة | 尾(蠍尾) |
| 觜 | نغايم يولدوز | ᠨᠠᡤᠠ ᡳᠮᠠ ᠶᡠᠯᡩᡠᠰ | nağāˀim | النعائم | 箕 |
| 參 | بلدە يولدوز | ᠪᠠᠯᡩᠠ ᠶᡠᠯᡩᡠᠰ | baldaʰ | البلدة | 斗 |
| 井 | دبيع يولدوز | ᡩᠠᠪᠠᡳ ᠶᡠᠯᡩᡠᠰ | dabayiˤ | سعد الذايح | 牛 |
| 鬼 | دبلغ يولدوز | ᠪᠠᠯᡳᠶᠠᡴ ᠶᡠᠯᡩᡠᠰ | baliğa | سعد بلع | 女(吞嚥) |
| 柳 | ڛعد ڛعود يولدوز | ᠰᠠᡤᠠᡨ ᠰᡠ ᡠᡨ ᠶᡠᠯᡩᡠᠰ | saˤad suˤuwd | سعد السعود | 虚 |
| 星 | ڛعد آخبيە يولدوز | ᠰᠠᡤᠠᡨ ᠠᡴᠪᠠᠶᠠ ᠶᡠᠯᡩᡠᠰ | saˤad ˀāxbaraʰ | سعد الأخبية | 危 |
| 張 | فرع مقدمە يولدوز | ᡦᠠᡵᠠ ᠮᡠᡴᠠᡨᡩᠠᠮᠠ ᠶᡠᠯᡩᡠᠰ | faraˤ muqadmaʰ | المقدم | 室 |
| 翼 | فرغ موخرّة يولدوز | ᡦᠠᡵᠠ ᠮᡠᡥᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | faraˤ muwxarraʰ | المؤخر | 壁 |
| 軫 | رشا يولدوز | ᡵᠠᡧᠠ ᠶᡠᠯᡩᡠᠰ | rašā | الرشاء | 奎(井繩) |
圖片版: 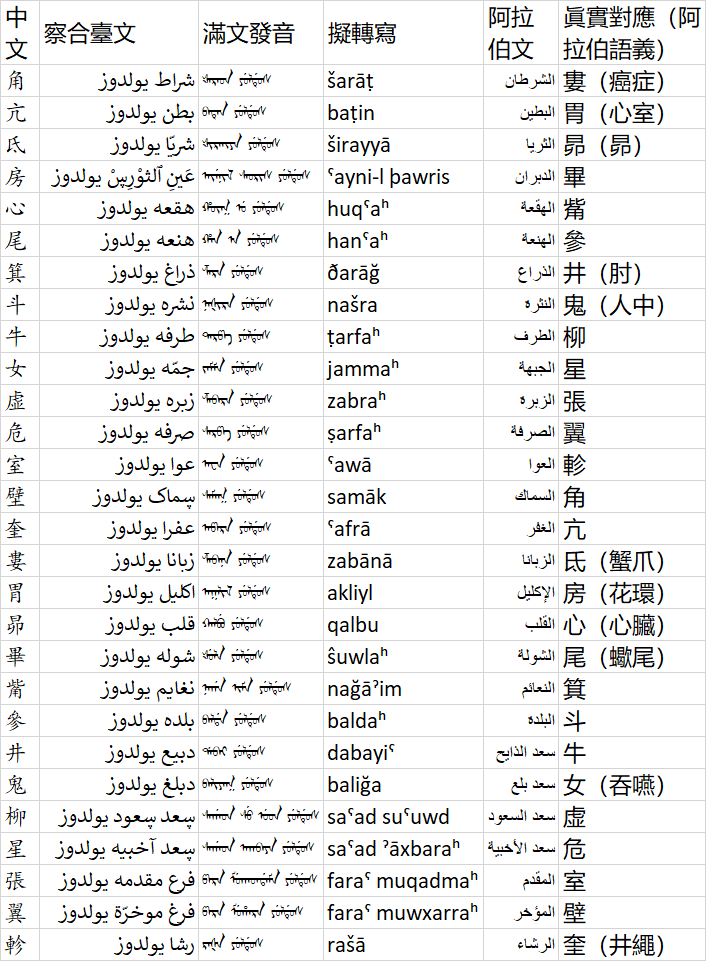
另附《五體清文鑑》二十八宿原文:
| 䈎碼 | 滿 | 藏 | 藏轉寫 | 藏注音 | 蒙 | 回 | 回注音 | 漢 |
|---|---|---|---|---|---|---|---|---|
| 22 | ᡤᡳᠮᡩᠠ᠈ | ནག་པ། | ᠨᠠᡴ ᠪᠠ | ᠨᠠᡴᠪᠠ | ᠽᠧᠳᠷᠠ᠂ | شراط يولدوز | ᡧᠠᡵᠠᡨ ᠶᡠᠯᡩᡠᠰ | 角 |
| 22 | ᠺᠠᠮᡩᡠᡵᡳ᠈ | ས་རིས། | ᠰᠠ ᡵᡳᠰ᠌ | ᠰᠠᡵᡳ | ᠰᠤᠸᠠᠳᠢ᠂ | بطن يولدوز | ᠪᠠᡨᡝᠨ ᠶᡠᠯᡩᡠᠰ | 亢 |
| 23 | ᡩᡳᠯᠪᡳᡥᡝ᠈ | ས་ག། | ᠰᠠ ᡤᠠ | ᠰᠠ ᡤᠠ | ᠱᠤᠱᠠᠭ᠂ | شريّا يولدوز | ᡧᡳᡵᠠᡳᠶᠠ ᠶᡠᠯᡩᡠᠰ | 氐 |
| 23 | ᡶᠠᠯᠮᠠᡥᡡᠨ᠈ | ལྷ་མཚམས། | ᢪᠠ ᠮᢣᡳᠶᠠᠮᠰ | ᠯᠠᡮᠠᠮ | ᠠᠨᠤᠷᠠᠳ᠂ | عَينِ ٱلثوْرِڛْ يولدوز | ᠠᠶᡝᠨᡳᠯ ᠰᠠᠣᡵᡳᠰ ᠶᡠᠯᡩᡠᠰ | 房 |
| 23 | ᠰᡳᠨᡩᡠᠪᡳ᠈ | སྣྲོན། | ᠰᠨᠠᡵᠣᠨ | ᠨᠣᡵᠣᠨ | ᠽᠧᠰᠳᠠ᠂ | هقعە يولدوز | ᡥᡡᡴ᠍ ᡠ ᠶᡠᠯᡩᡠᠰ | 心 |
| 23 | ᠸᡝᡳᠰᡥᠠ᠈ | སྣྲུབས། | ᠰᠨᠠᡵᡠᠪᠰ | ᠨᡠᡵᡠᠪ | ᠮᠣᠯ᠂ | هنعە يولدوز | ᡥᠠᠨ ᠠ ᠶᡠᠯᡩᡠᠰ | 尾 |
| 24 | ᡤᡳᡵᡥᠠ᠈ | ཆུ་སྟོད། | ᠴᡠ ᠰᢠᠣᡨ | ᠴᡠᡩᠣᡨ | ᠪᠤᠷᠸᠠᠰᠠᠳ᠂ | ذراغ يولدوز | ᡯᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | 箕 |
| 24 | ᡩᡝᠮᡨᡠ᠈ | ཆུ་སྨད། | ᠴᡠ ᠰᠮᠠᡨ | ᠴᡠᠮᠠᡨ | ᠣᠳᠢᠷᠠᠰᠠᠳ᠂ | نشرە يولدوز | ᠨᠠᡧᡳᡵᠠ ᠶᡠᠯᡩᡠᠰ | 斗 |
| 24 | ᠨᡳᠣᡥᠠᠨ᠈ | གྲོ་ཞུན། | ᡤᡵᠣ ᢤᡠᠨ | ᠵᠣᡧᡠᠨ | ᠠᠪᠢᠽᠢ᠂ | طرفە يولدوز | ᡨᠠᡵᡦᠠ ᠶᡠᠯᡩᡠᠰ | 牛 |
| 24 | ᠨᡳᡵᡝᡥᡝ᠈ | བྱི་ཞུན། | ᠪᠶᡳ ᢤᡠᠨ | ᠵᡳ ᡧᡠᠨ | ᠰᠢᠷᠡᠸᠡᠨ᠂ | جمّە يولدوز | ᠵᠠᠮᠮᠠ ᠶᡠᠯᡩᡠᠰ | 女 |
| 25 | ᡥᡳᠩᡤᡝᡵᡳ᠈ | མོན་གྲུ། | ᠮᠣᠨ ᡤᡵᡠ | ᠮᠣᠨᡵᡠ | ᠳ᠋ᠠᠨᠢᠰᠲᠠ᠂ | زبرە يولدوز | ᡯᠠᠪᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | 虚 |
| 25 | ᠸᡝᡳᠪᡳᠨ᠈ | སོན་གྲེ། | ᠮᠣᠨ ᡤᡵᡝ | ᠮᠣᠨᡵᡝ | ᠰᠠᠳᠠᠪᠢᠨ᠂ | صرفە يولدوز | ᠰᠠᡵᡦᠠ ᠶᡠᠯᡩᡠᠰ | 危 |
| 25 | ᡧᡳᠯᡤᡳᠶᠠᠨ᠈ | ཁྲུམས་ལྟོད། | ᠺᡵᡠᠮᠰ ᠰᢠᠣᡨ | ᠴᡠᠮᡩᠣᡨ | ᠪᠤᠷᠸᠠᠪᠠᠳᠢᠷᠠᠪᠠᠳ᠂ | عوا يولدوز | ᠠᠸᠠ ᠶᡠᠯᡩᡠᠰ | 室 |
| 25 | ᠪᡳᡴᡳᡨᠠ᠈ | ཁྲུམས་སྨད། | ᠺᡵᡠᠮᠰ ᠰᠮᠠᡨ | ᠴᡠᠮ ᠮᠠᡨ | ᠤᠳᠢᠷᠠᠪᠠᠳᠢᠷᠠᠪᠠᠳ᠂ | ڛماک يولدوز | ᠰᠠᠮᠠᡴ ᠶᡠᠯᡩᡠᠰ | 壁 |
| 26 | ᡴᡠᡳᠨᡳᡥᡝ᠈ | ནམ་གྲུ། | ᠨᠠᠮ ᡤᡵᡠ | ᠨᠠᠮᡵᡠ | ᠷᠢᠷᠡᠳᠢ᠂ | عفرا يولدوز | ᠠᡦᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | 奎 |
| 26 | ᠯᡠᡩᠠᡥᡡᠨ᠈ | ཐ་སྐར་། | ᡨᠠ ᠰᡬᠠᡵ | ᡨᠠᠰᡬᠠᡵ | ᠠᠱᠤᠸᠠᠨᠢ᠂ | زبانا يولدوز | ᡯᠠᠪᠠᠨᠠ ᠶᡠᠯᡩᡠᠰ | 婁 |
| 26 | ᠸᡝᠯᡥ᠋ᡡᠮᡝ᠈ | པྲ་ཉེ། | ᢒᡵᠠ ᠨᡳᠶᡝ | ᠪᠠᡵᠠᠨᡳᠶᡝ | ᠪᠷᠠᠨᠢ᠂ | اكليل يولدوز | ᠠᡴᠯᡳᠯ ᠶᡠᠯᡩᡠᠰ | 胃 |
| 26 | ᠮᠣᡴᠣ᠈ | སྨིན་དྲུག། | ᠰᠮᡳᠨ ᡩᡵᡠᡴ | ᠮᡳᠨᠵᡠᡴ | ᠭᠢᠷᠳᠢᠭ᠂ | قلب يولدوز | ᡴᠠᠯᠪᡠ ᠶᡠᠯᡩᡠᠰ | 昴 |
| 27 | ᠪᡳᠩᡥᠠ᠈ | སྣར་མ། | ᠰᠨᠠᡵ ᠮᠠ | ᠨᠠᡵᠮᠠ | ᠷᠤᠸᠠᠭᠢᠨᠢ᠂ | شولە يولدوز | ᡧᡠᠯᠠ ᠶᡠᠯᡩᡠᠰ | 畢 |
| 27 | ᠰᡝᠮᠨᡳᠣ᠈ | མགོ། | ᠮᡤᠣ | ᡤᠣ | ᠮᠠᠷᠺᠠᠰᠠᠷ᠂ | نغايم يولدوز | ᠨᠠᡤᠠ ᡳᠮᠠ ᠶᡠᠯᡩᡠᠰ | 觜 |
| 27 | ᡧᡝᠪᠨᡳᠣ᠈ | ལག། | ᠯᠠᡴ | ᠯᠠᡴ | ᠠᠷᠳᠢᠷ᠂ | بلدە يولدوز | ᠪᠠᠯᡩᠠ ᠶᡠᠯᡩᡠᠰ | 參 |
| 27 | ᠵᡳᠩᠰᡳᡨᡠᠨ᠈ | ནབས་སོ། | ᠨᠠᠪᠰ ᠰᠣ | ᠨᠠᠪᠰᠣ | ᠪᠤᠷᠨᠠᠸᠠᠱᠤ᠂ | دبيع يولدوز | ᡩᠠᠪᠠᡳ ᠶᡠᠯᡩᡠᠰ | 井 |
| 28 | ᡤᡠᡳᠨᡳ᠈ | རྒྱལ། | ᡵᡤᠶᠠᠯ | ᠵᠠᠯ | ᠪᠦᠨ᠂ | بلغ يولدوز | ᠪᠠᠯᡳᠶᠠᡴ ᠶᡠᠯᡩᡠᠰ | 鬼 |
| 28 | ᠯᡳᡵᡥᠠᠨ᠈ | སྐག། | ᠰᡬᠠᡴ | ᡬᠠᡴ | ᠠᠰᠯᠢᠨ᠂ | ڛعد ڛعود يولدوز | ᠰᠠᡤᠠᡨ ᠰᡠ ᡠᡨ ᠶᡠᠯᡩᡠᠰ | 柳 |
| 28 | ᠰᡳᠮᠣᡵᡳ᠈ | མཆུ། | ᠮᠴᡠ | ᠴᡠ | ᠮᠧᠭ᠂ | ڛعد آخبيە يولدوز | ᠰᠠᡤᠠᡨ ᠠᡴᠪᠠᠶᠠ ᠶᡠᠯᡩᡠᠰ | 星 |
| 28 | ᠵᠠᠪᡥᡡ᠈ | གྲེ། | ᡤᡵᡝ | ᠵᡝ | ᠪᠤᠷᠸᠠᠹᠠᠯᠭᠦᠨᠢ᠂ | فرع مقدمە يولدوز | ᡦᠠᡵᠠ ᠮᡠᡴᠠᡨᡩᠠᠮᠠ ᠶᡠᠯᡩᡠᠰ | 張 |
| 29 | ᡳᠮᡥᡝ᠈ | དབོ། | ᡩᠪᠣ | ᠪᠣ | ᠤᠳᠢᠷᠠᠹᠠᠯᠭᠦᠨᠢ᠂ | فرغ موخرّة يولدوز | ᡦᠠᡵᠠ ᠮᡠᡥᠠᡵᠠ ᠶᡠᠯᡩᡠᠰ | 翼 |
| 29 | ᠵᡝᡨᡝᠨ᠈ | མེ་བཞི། | ᠮᡝ ᡤᢤᡳ | ᠮᡝᡧᡳ | ᠬᠠᠰᠳᠠ᠂ | رشا يولدوز | ᡵᠠᡧᠠ ᠶᡠᠯᡩᡠᠰ | 軫 |
圖片版: 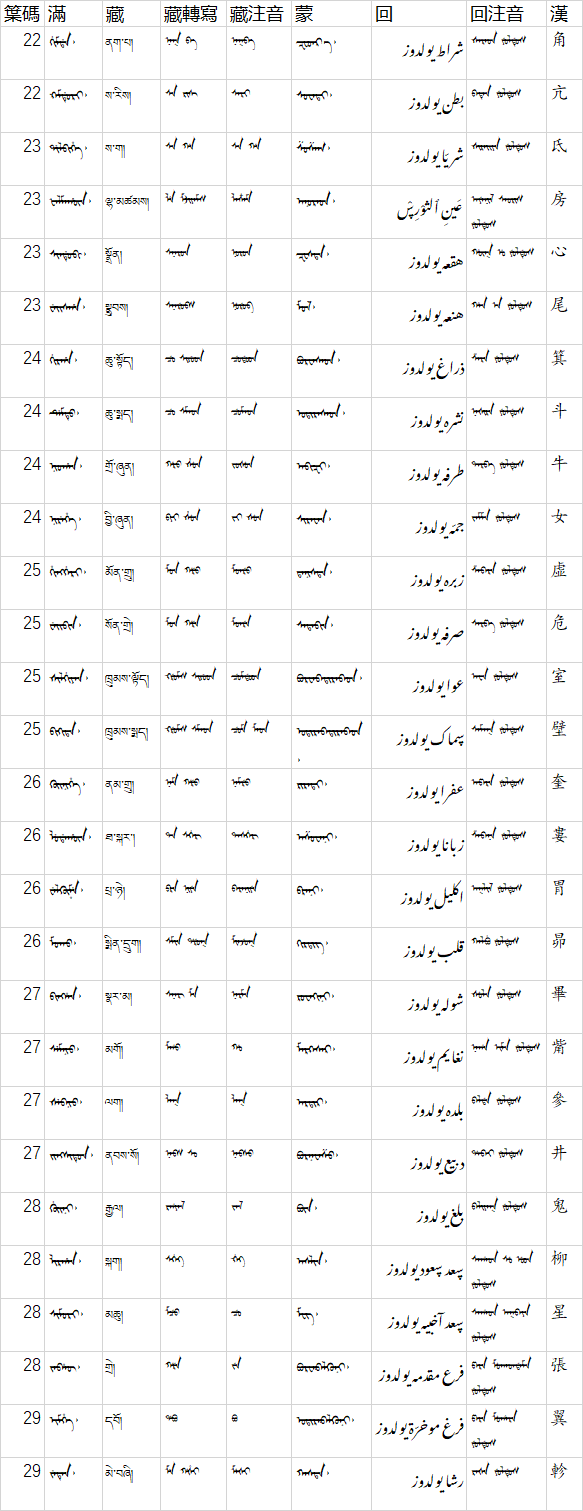
有錯誤處歡迎糾正。